I am currently a 3rd-year PhD student in Computer Science at The University of Hong Kong (HKU), supervised by Prof. Ping Luo. My research focuses on multimodal foundation models, especially unified systems that connect visual understanding, generation, and evaluation. My earlier work explored deepfake detection and AI interpretability. I have been a research intern at Hunyuan (Tencent Project Up), Huawei Noah’s Ark Lab, and Megvii. Before joining HKU, I obtained my master’s degree from the University of Chinese Academy of Sciences under Prof. Chao Li, and received my bachelor’s degree from Dalian University of Technology (DLUT). I am expected to graduate in July 2027 and am actively looking for job opportunities.
Education
PhD in Computer Science
MEng in Electronic Engineering
BEng in Digital Media Technology
Publications
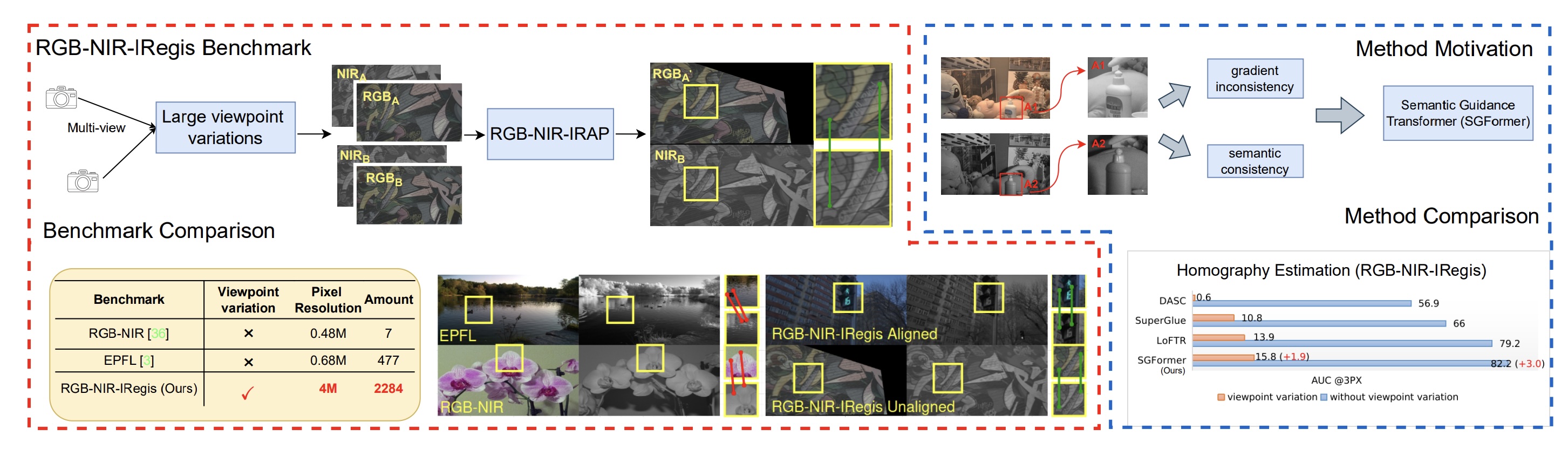
Unified Multimodal Understanding & Generation

In NeurIPS 2025 (Spotlight)
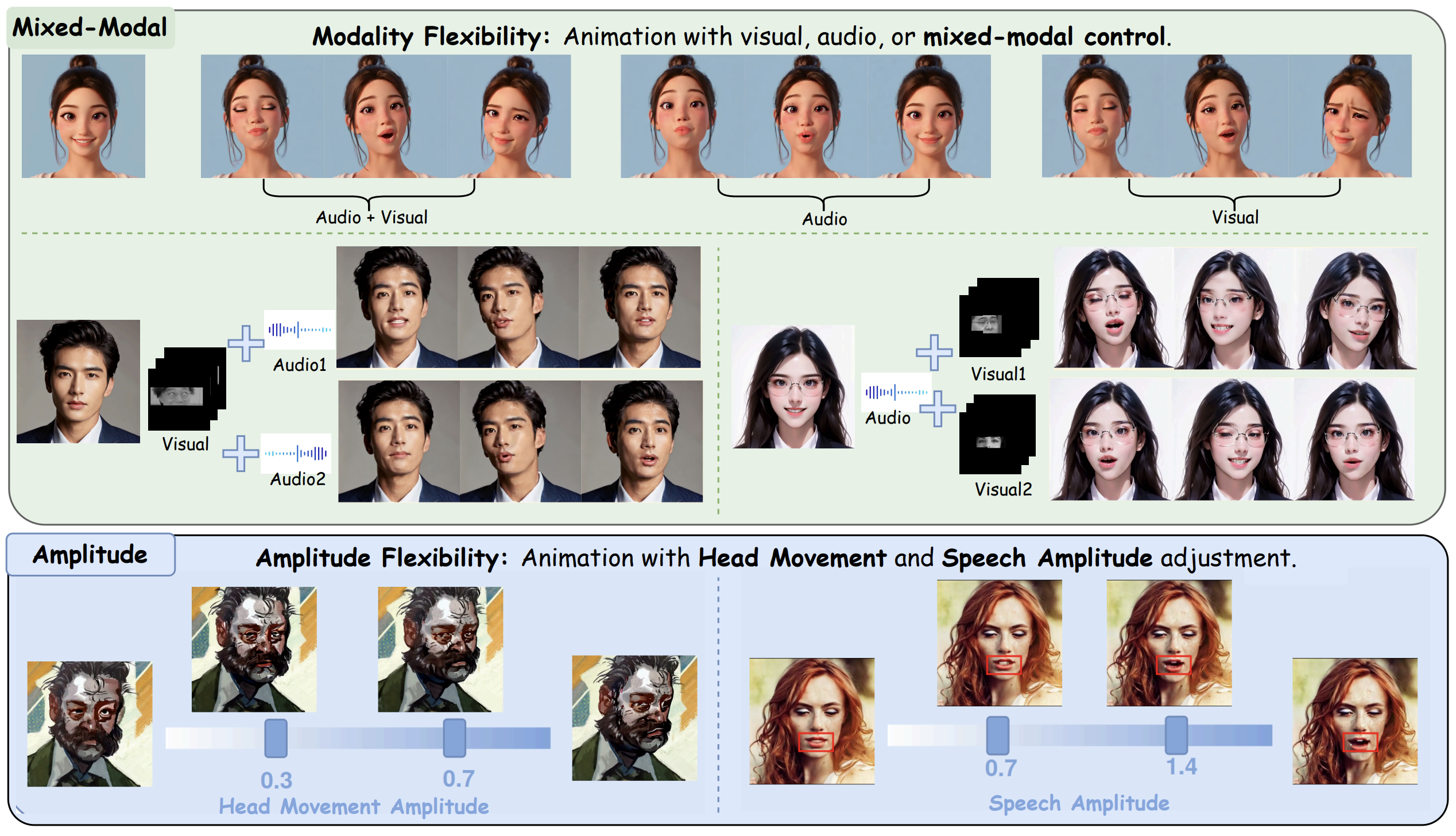
Multimodal Generation
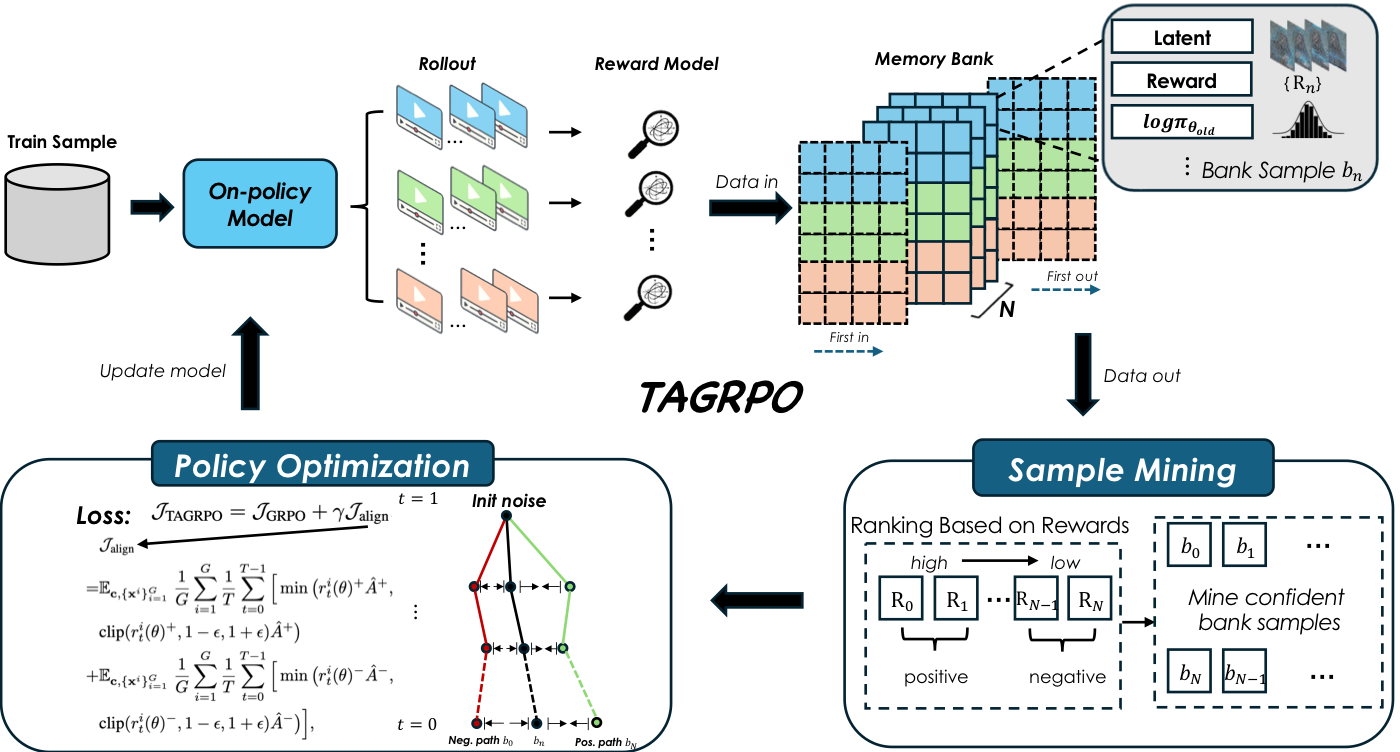
To appear in ICML 2026

Multimodal Understanding
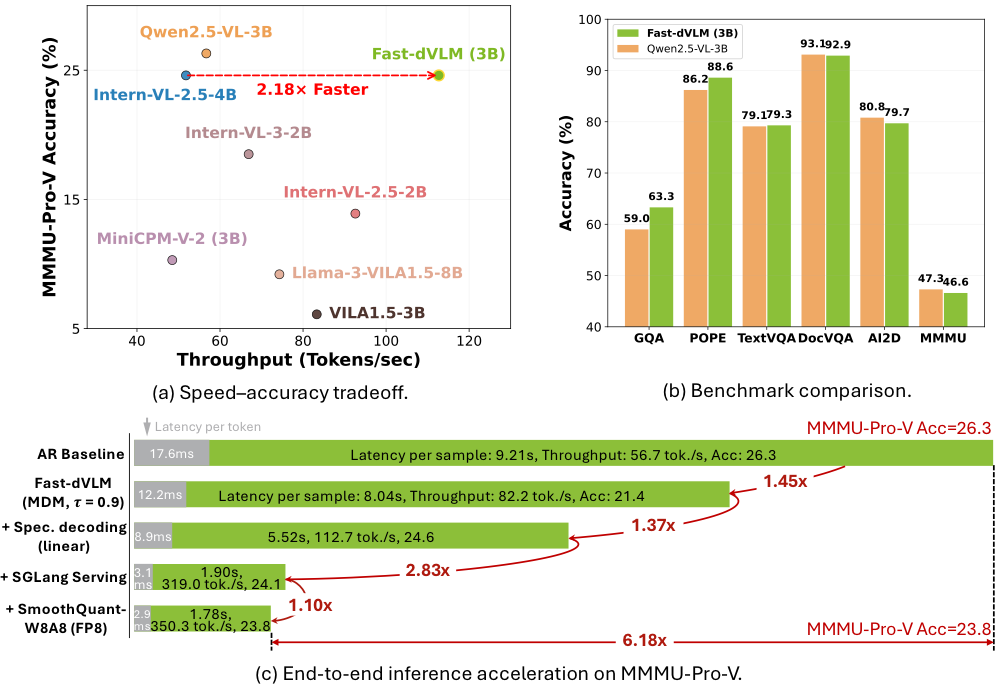

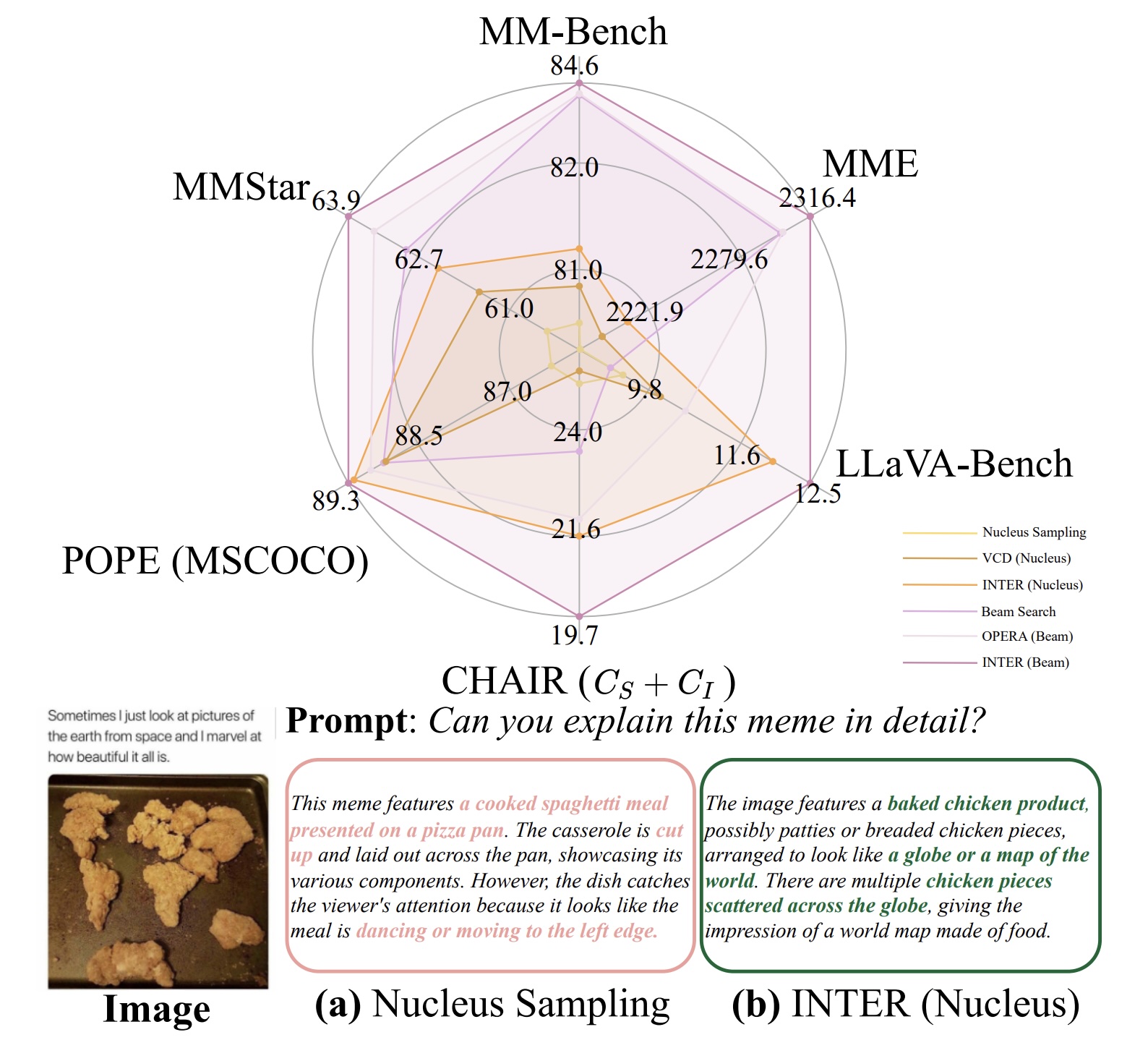
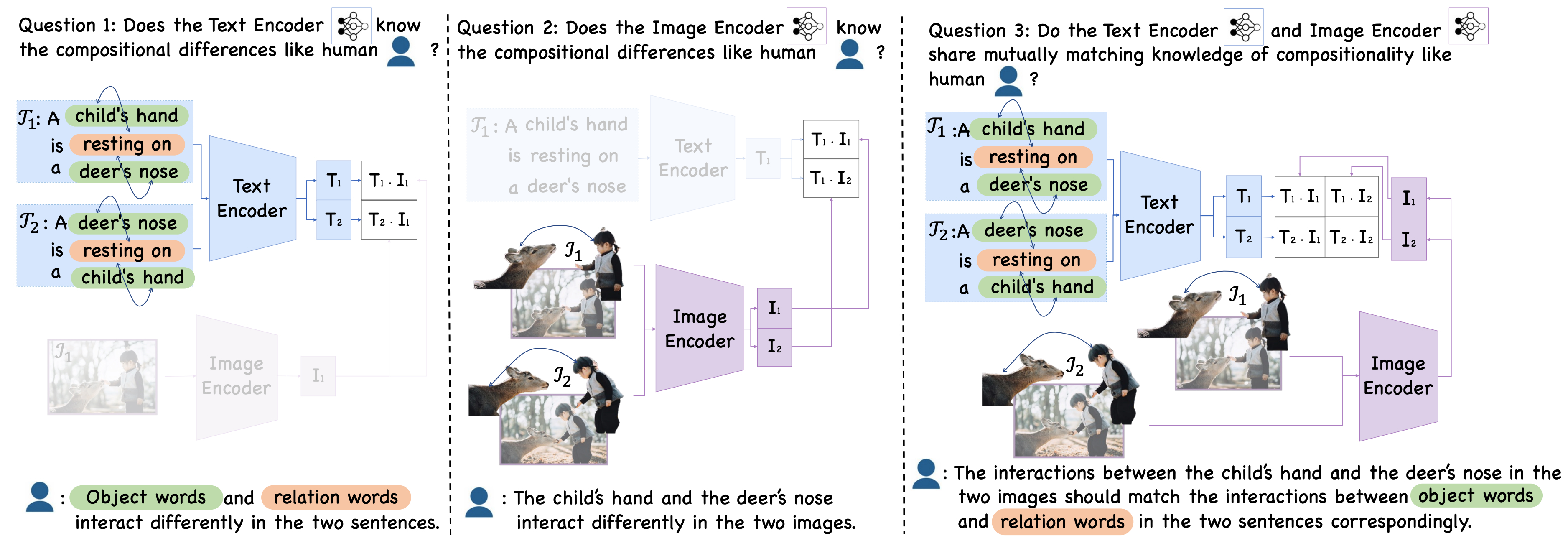
Multimodal Evaluation
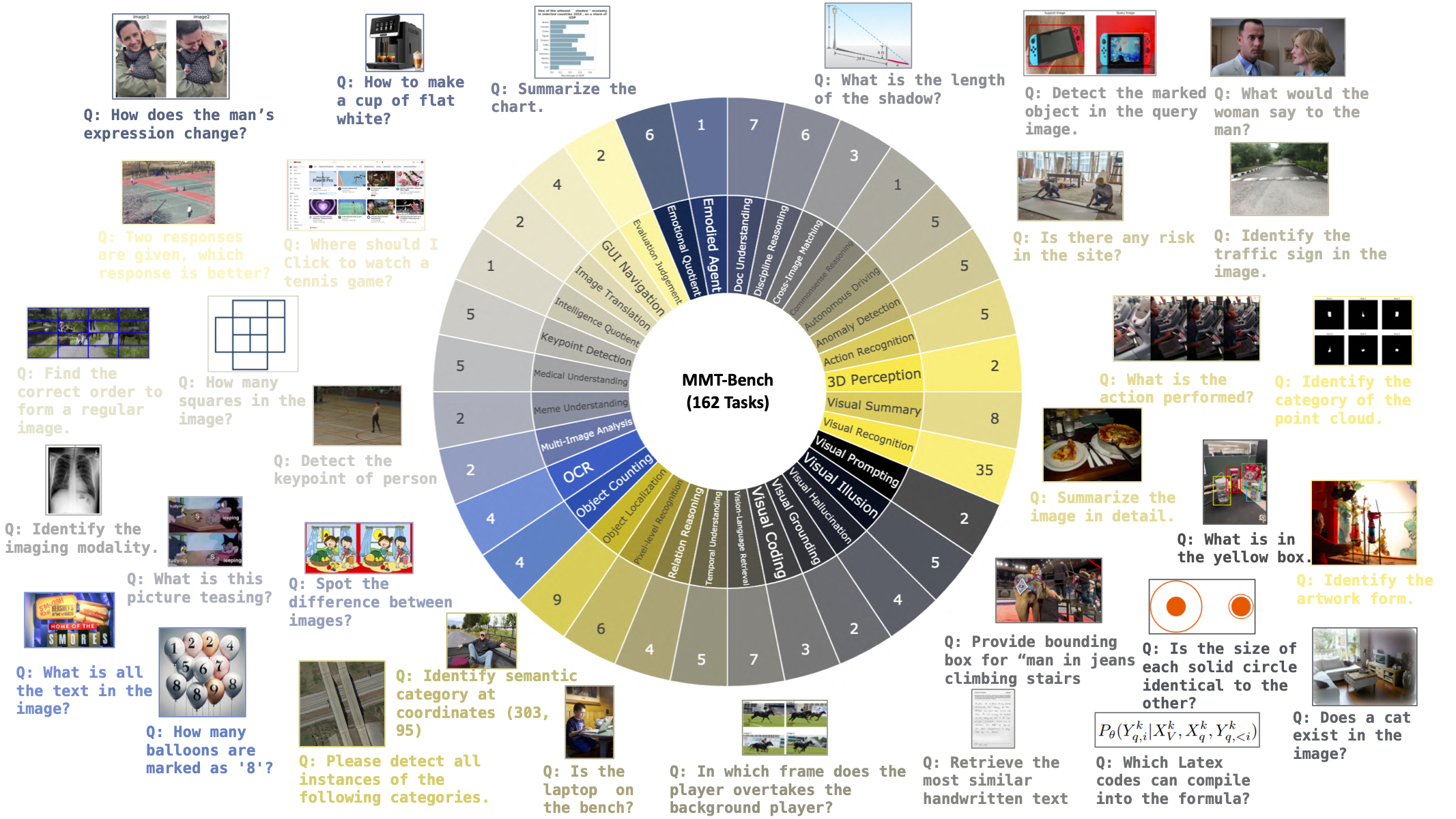
Deepfake Detection
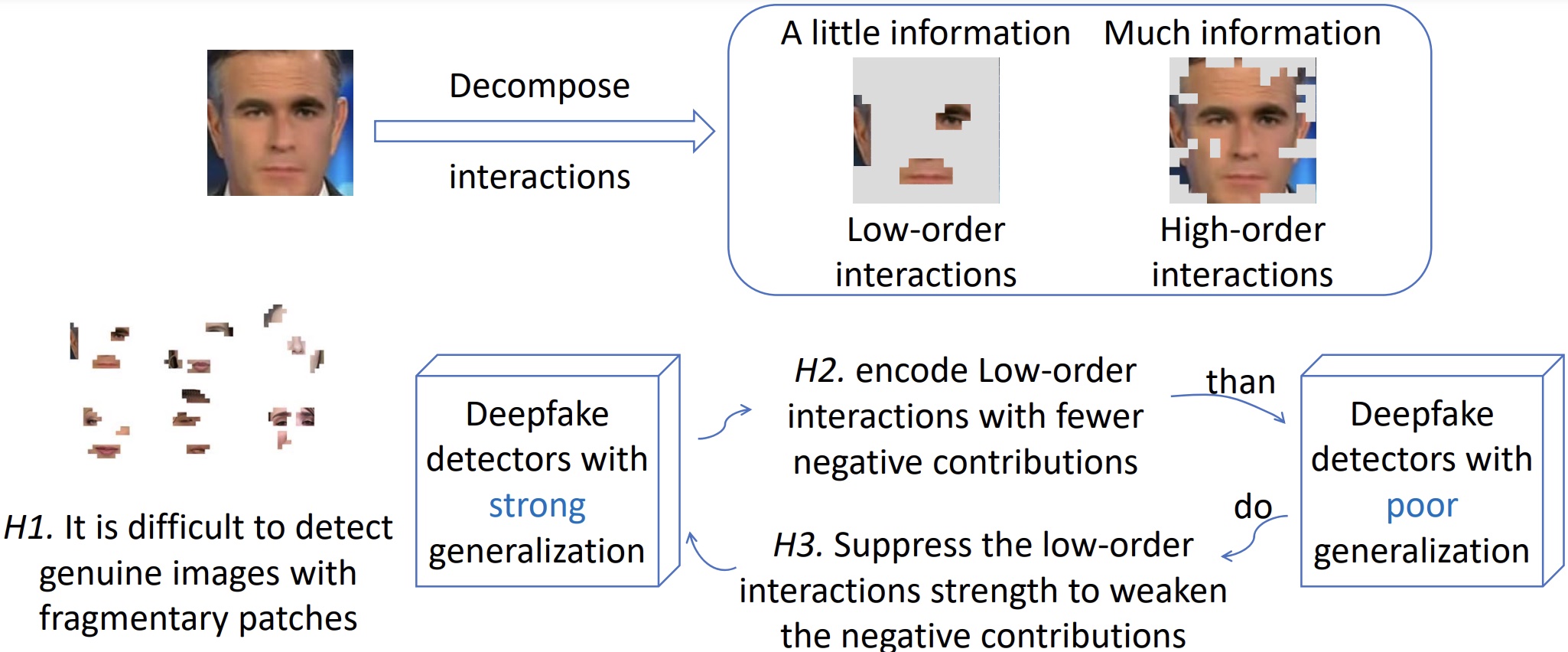
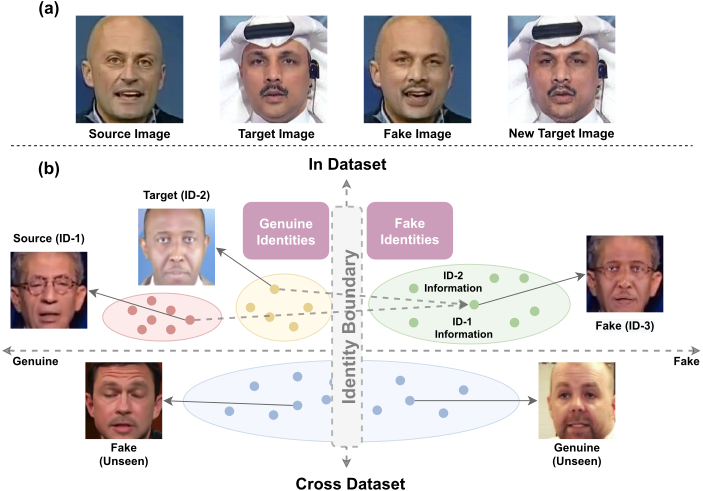


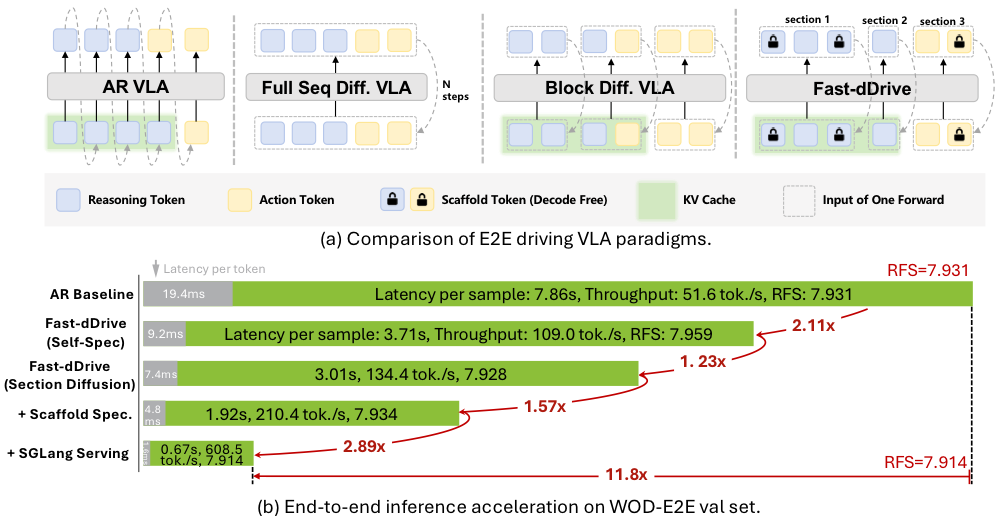
Additional Research