Jin Wang
Jin Wang
Home
Education
Publications
Light
Dark
Automatic
1
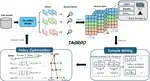
TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment
Jin Wang
,
Jianxiang Lu
,
Guangzheng Xu
,
Comi Chen
,
Haoyu Yang
,
Linqing Wang
,
Peng Chen
,
Mingtao Chen
,
Zhichao Hu
,
Longhuang Wu
,
Shuai Shao
,
Qinglin Lu
,
Ping Luo
PDF
Cite
Megactor-sigma: Unlocking flexible mixed-modal control in portrait animation with diffusion transformer
Diffusion models have demonstrated superior performance in portrait animation. However, current approaches relied on either visual or …
Shurong Yang
,
Huadong Li
,
Juhao Wu
,
Minhao Jing
,
Linze Li
,
Renhe Ji
,
Jiajun Liang
,
Haoqiang Fan
,
Jin Wang
PDF
Cite
Code
Cross-modal Identity Mapping: Minimizing Information Loss in Modality Conversion via Reinforcement Learning
Haonan Jia
,
Shichao Dong
,
Xin Dong
,
Zenghui Sun
,
Jin Wang
,
Jinsong Lan
,
Xiaoyong Zhu
,
Bo Zheng
,
Kaifu Zhang
PDF
Asymmetric Cross-Modal Knowledge Distillation: Bridging Modalities with Weak Semantic Consistency
Riling Wei
,
Kelu Yao
,
Chuanguang Yang
,
Jin Wang
,
Zhuoyan Gao
,
Chao Li
PDF
FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify …
Jin Wang
,
Yao Lai
,
Aoxue Li
,
Shifeng Zhang
,
Jiacheng Sun
,
Ning Kang
,
Chengyue Wu
,
Zhenguo Li
,
Ping Luo
PDF
Cite
Code
Project
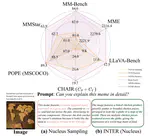
INTER: Mitigating Hallucination in Large Vision-Language Models by Interaction Guidance Sampling
Hallucinations in large vision-language models (LVLMs) pose significant challenges for real-world applications, as LVLMs may generate …
Xin Dong
,
Shichao Dong
,
Jin Wang
,
Jing Huang
,
Li Zhou
,
Zenghui Sun
,
Lihua Jing
,
Jingsong Lan
,
Xiaoyong Zhu
,
Bo Zheng
PDF
Cite
Forensics-Bench: A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models
Recently, the rapid development of AIGC has significantly boosted the diversities of fake media spread in the Internet, posing …
Jin Wang
,
Chenghui Lv
,
Xian Li
,
Shichao Dong
,
Huadong Li
,
Kelu Yao
,
Chao Li
,
Wenqi Shao
,
Ping Luo
PDF
Cite
Code
Dataset
Project
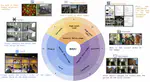
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced …
Fanqing Meng
,
Jin Wang
,
Chuanhao Li
,
Quanfeng Lu
,
Hao Tian
,
Jiaqi Liao
,
Xizhou Zhu
,
Jifeng Dai
,
Yu Qiao
,
Ping Luo
,
Kaipeng Zhang
,
Wenqi Shao
PDF
Cite
Code
Dataset
Project
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
It is widely believed that sparse supervision is worse than dense supervision in the field of depth completion, but the underlying …
Huadong Li
,
Minhao Jing
,
Jin Wang
,
Shichao Dong
,
Jiajun Liang
,
Haoqiang Fan
,
Renhe Ji
PDF
Code
Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show …
Jin Wang
,
Shichao Dong
,
Yapeng Zhu
,
Kelu Yao
,
Weidong Zhao
,
Chao Li
,
Ping Luo
PDF
Cite
Code
Project
»
Cite
×