Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
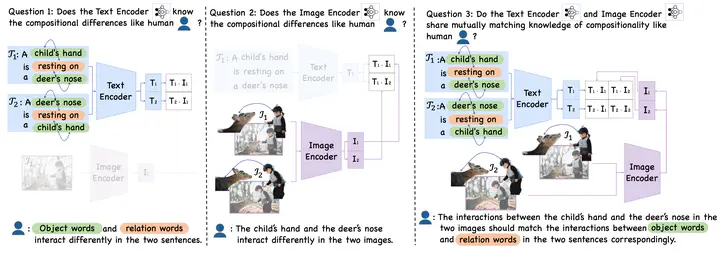 Diagnosing the compositional reasoning capabilities of Vision Language Models (VLMs).
Diagnosing the compositional reasoning capabilities of Vision Language Models (VLMs).Abstract
Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show that current Vision Language Models (VLMs) surprisingly lack sufficient knowledge with respect to such capabilities. To this end, we propose to thoroughly diagnose the composition representations encoded by VLMs, systematically revealing the potential cause for this weakness. Specifically, we propose evaluation methods from a novel game-theoretic view to assess the vulnerability of VLMs on different aspects of compositional understanding, e.g., relations and attributes. Extensive experimental results demonstrate and validate several insights to understand the incapabilities of VLMs on compositional reasoning, which provide useful and reliable guidance for future studies.